
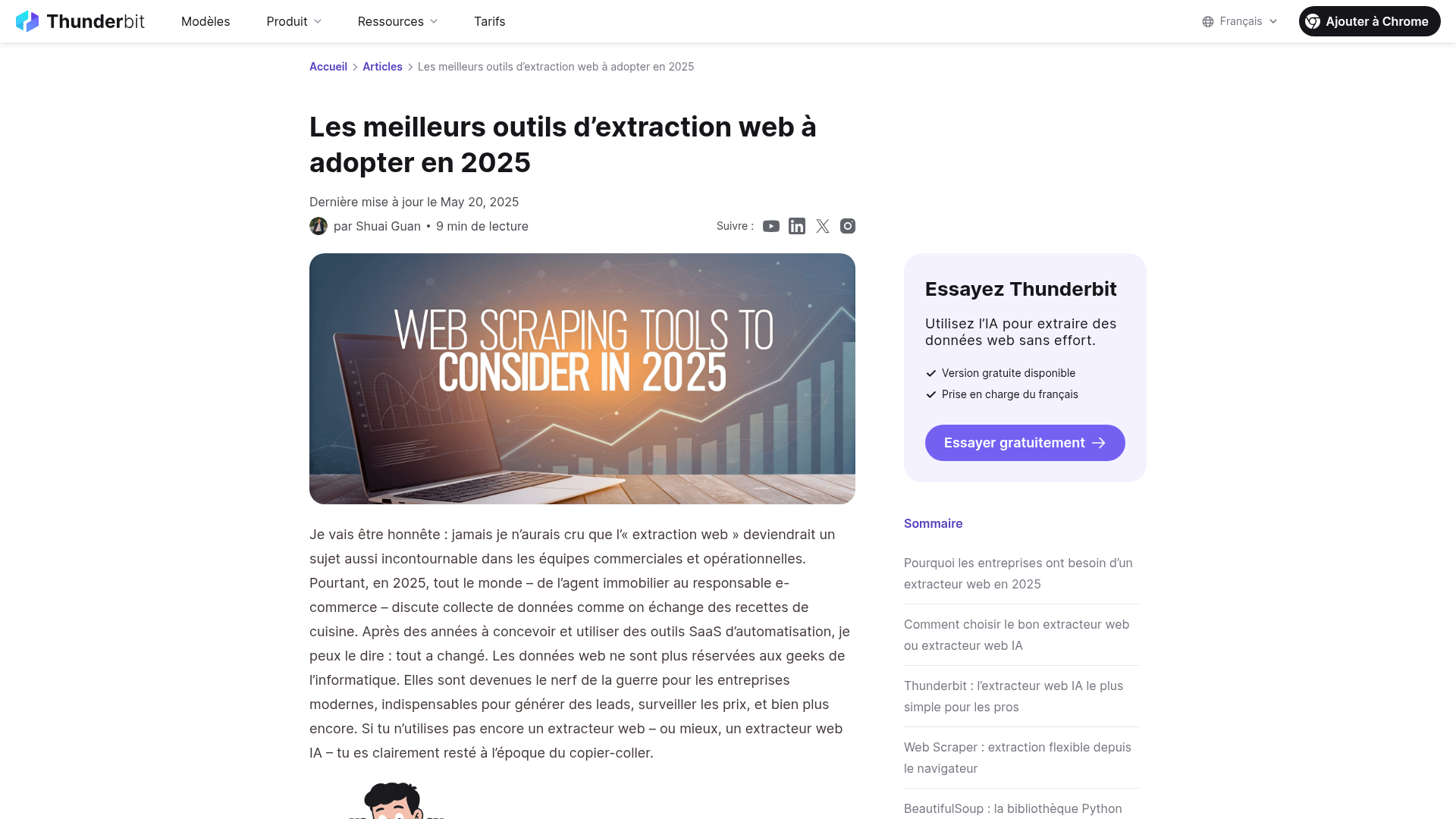
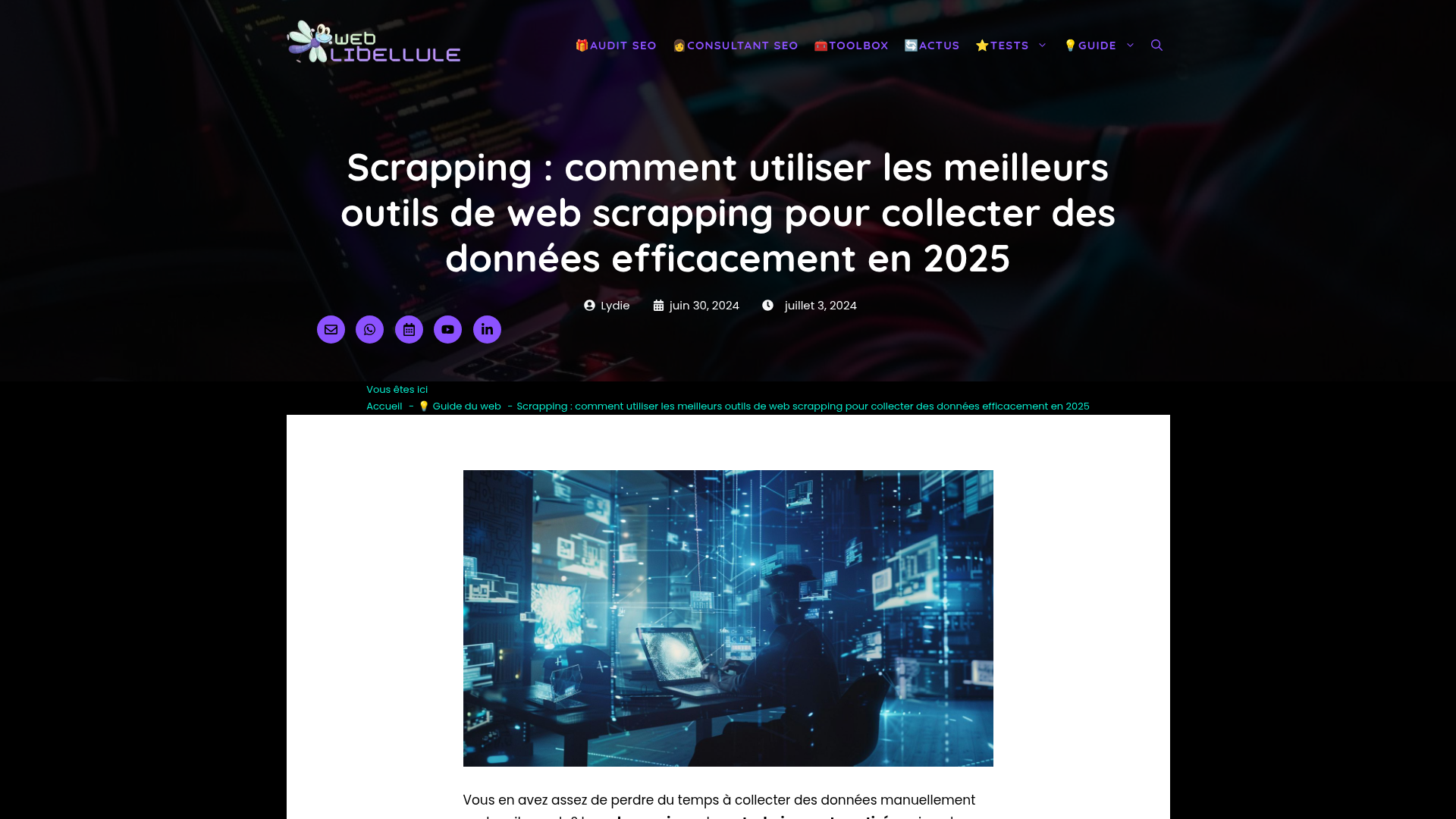
En 2025, l'extraction de données web via Chrome, ou chrome web scraping, est devenue une compétence indispensable pour les professionnels de tous secteurs. Fini le temps où cette pratique était réservée aux développeurs et experts en informatique. Aujourd'hui, les équipes commerciales, marketing et opérationnelles l'utilisent quotidiennement pour collecter des informations stratégiques. Cependant, beaucoup de professionnels perdent encore un temps précieux avec des méthodes manuelles de copier-coller, ralentissant leur productivité et limitant leur potentiel d'analyse. Face à l'évolution constante des sites web et des techniques d'extraction, il devient crucial de maîtriser les meilleures pratiques pour obtenir efficacement les données dont vous avez besoin. Dans cet article, nous allons explorer des conseils pratiques pour optimiser votre processus d'extraction de données via Chrome en 2025, en mettant l'accent sur des solutions sans code comme Sheetly.ai qui permettent d'automatiser ce travail fastidieux et de transformer des données brutes en informations exploitables.
Astuce #1 : Choisir la bonne extension de web scraping pour Chrome
La première étape cruciale pour réussir votre projet de web scraping chrome est de sélectionner l'extension adaptée à vos besoins spécifiques. En 2025, le marché des extensions d'extraction de données s'est considérablement développé, offrant une variété d'options avec des fonctionnalités distinctes.
Lors de votre sélection, privilégiez les extensions offrant:
- Une interface intuitive permettant d'extraire des données sans écrire de code
- La reconnaissance intelligente des éléments structurés sur les pages web
- La capacité à traiter différents formats (tableaux, listes, PDF, images)
- L'intégration directe avec vos outils de productivité habituels (Google Sheets, Notion, Excel)
- Des fonctionnalités d'automatisation pour les extractions récurrentes
Les outils d'extraction web modernes varient considérablement en termes de capacités et de facilité d'utilisation. Certains sont conçus pour des cas d'usage simples, tandis que d'autres peuvent gérer des scénarios complexes impliquant du contenu dynamique ou des sites protégés.
Les extensions les plus performantes en 2025 utilisent l'intelligence artificielle pour identifier automatiquement les structures de données, ce qui réduit considérablement le temps de configuration. Cette détection intelligente permet d'extraire rapidement des informations organisées sans avoir à spécifier manuellement chaque élément à capturer.
Astuce #2 : Définir clairement vos objectifs d'extraction
Avant de vous lancer dans l'extraction de données, prenez le temps de définir précisément vos objectifs. Cette étape préliminaire, souvent négligée, est pourtant déterminante pour l'efficacité de votre web scraping google chrome.
Commencez par vous poser les questions suivantes:
- Quelles données spécifiques dois-je extraire? (noms, prix, descriptions, coordonnées...)
- À quelle fréquence ai-je besoin de ces données? (une fois, quotidiennement, hebdomadairement)
- Comment vais-je utiliser ces informations? (analyse, prospection, veille concurrentielle)
- Quel format de données sera le plus adapté à mon objectif final?
Une approche structurée consiste à créer un document préparatoire listant tous les champs de données nécessaires. Cette cartographie vous permettra de configurer plus efficacement votre extension de web scraping extension chrome et d'éviter de perdre du temps à extraire des informations non pertinentes.
Pour les projets complexes impliquant plusieurs sources de données, envisagez de définir un processus méthodique d'extraction et de nettoyage. Cette organisation préalable optimisera considérablement votre flux de travail et la qualité des données obtenues.
En identifiant clairement vos objectifs, vous pourrez également mieux sélectionner les pages web les plus pertinentes pour votre extraction, réduisant ainsi le volume de données à traiter et accélérant l'ensemble du processus.
Astuce #3 : Respecter les conditions d'utilisation des sites web et les fichiers robots.txt
En 2025, la dimension éthique et légale du web scraping chrome est plus importante que jamais. Les réglementations concernant la protection des données se sont renforcées, et de nombreux sites web ont mis en place des mesures pour contrôler l'extraction de leurs contenus.
Pour une pratique responsable du chrome web scraping:
- Consultez systématiquement les conditions d'utilisation du site avant toute extraction
- Vérifiez le fichier robots.txt qui indique les sections autorisées ou interdites pour les robots
- Respectez les limites de taux d'extraction pour ne pas surcharger les serveurs (rate limiting)
- Ne collectez jamais de données personnelles sans consentement explicite
- Identifiez-vous via votre user-agent lors des extractions importantes
Il est également crucial d'adapter votre cadence d'extraction pour imiter un comportement humain. Les extractions trop rapides ou trop massives peuvent être interprétées comme des attaques par les systèmes de sécurité des sites web, entraînant le blocage de votre adresse IP.
La conformité avec le RGPD et autres réglementations similaires n'est pas optionnelle. En cas de non-respect, vous vous exposez à des sanctions financières potentiellement importantes ainsi qu'à des risques de réputation pour votre entreprise.
Les outils d'extraction sans code modernes intègrent généralement des fonctionnalités de conformité automatique qui vous aident à respecter ces bonnes pratiques sans effort supplémentaire de votre part.
Astuce #4 : Gérer avec soin le contenu dynamique
L'une des difficultés majeures du web scraping chrome extension en 2025 concerne l'extraction de contenu dynamique. De nombreux sites web modernes utilisent des technologies comme JavaScript, AJAX ou React pour charger le contenu de manière asynchrone après le chargement initial de la page.
Pour extraire efficacement ces données dynamiques:
- Utilisez des extensions capables d'interagir avec le DOM après le chargement JavaScript
- Configurez des délais d'attente appropriés pour que le contenu ait le temps de s'afficher
- Identifiez les déclencheurs d'événements qui font apparaître certaines données (clics, scrolls)
- Préférez les outils avec des fonctionnalités de rendu côté client intégrées
- Testez vos extractions sur différentes conditions de réseau pour assurer leur fiabilité
Les sites à pagination infinie ou ceux qui chargent du contenu au scroll représentent un défi particulier. Les solutions avancées de web scraping peuvent automatiser ces interactions pour récupérer l'ensemble des données, même celles initialement invisibles.
Pour les sites particulièrement complexes, comme les applications web single-page (SPA), privilégiez les solutions d'automatisation qui peuvent interagir naturellement avec l'interface utilisateur comme le ferait un humain.

Les technologies d'extraction basées sur l'IA sont particulièrement efficaces face au contenu dynamique, car elles peuvent analyser et comprendre la structure logique d'une page au-delà de son simple code HTML, identifiant les modèles de données indépendamment de leur méthode de chargement.
Astuce #5 : Nettoyer et structurer efficacement vos données
L'extraction n'est que la première étape. Pour tirer pleinement parti de votre web scraping via Chrome, vous devez transformer les données brutes en informations structurées et exploitables. En 2025, cette étape de nettoyage est devenue largement automatisée grâce aux outils intelligents.
Voici les pratiques essentielles pour optimiser le traitement post-extraction:
- Standardisez les formats de données (dates, devises, unités de mesure)
- Éliminez les doublons et les entrées incomplètes
- Créez une taxonomie cohérente pour catégoriser vos informations
- Enrichissez vos données avec des sources complémentaires
- Documentez votre processus de nettoyage pour assurer la reproductibilité
Les solutions modernes d'extraction de données intègrent désormais des fonctionnalités avancées de reconnaissance de patterns qui identifient automatiquement la structure sous-jacente des données, même lorsqu'elles proviennent de sources hétérogènes.
Pour maximiser l'efficacité de votre analyse, envisagez d'utiliser des automatisations d'extraction de données qui peuvent non seulement collecter les informations, mais aussi les transformer directement dans le format souhaité, réduisant ainsi considérablement le temps de traitement.
La normalisation des données est particulièrement importante lorsque vous consolidez des informations provenant de multiples sources. Sans cette étape, vos analyses risquent d'être faussées par des incohérences de format ou des variations terminologiques.
Astuce bonus : Automatiser entièrement votre flux d'extraction de données
Pour porter votre chrome web scraping au niveau supérieur en 2025, l'automatisation complète du processus d'extraction représente un avantage compétitif majeur. Les professionnels les plus performants ne se contentent plus d'extraire des données ponctuellement, mais mettent en place des systèmes d'extraction programmés.
Une automatisation complète comprend:
- La planification d'extractions récurrentes à intervalles définis
- La détection automatique des changements dans la structure des sites cibles
- L'enrichissement et le nettoyage automatisés des données extraites
- La notification en cas d'anomalies ou de données manquantes
- L'intégration directe avec vos outils d'analyse et vos dashboards
Les outils d'extraction basés sur l'IA comme Sheetly.ai vont encore plus loin en s'adaptant intelligemment aux modifications des sites web. Contrairement aux extracteurs traditionnels qui peuvent échouer lorsque la structure d'une page change, ces solutions modernes identifient les données par leur signification sémantique plutôt que par leur position dans le code HTML.
Cette approche intelligente du web scraping permet de maintenir la continuité de vos flux de données même lorsque les sites sources évoluent, un avantage crucial pour les analyses à long terme et la veille concurrentielle.
En automatisant l'ensemble du processus, de l'extraction à l'analyse, vous libérez un temps précieux que vous pouvez consacrer à l'interprétation stratégique des données plutôt qu'à leur collecte technique.
La transformation numérique par l'extraction intelligente de données
L'extraction de données web via Chrome en 2025 s'est considérablement transformée, passant d'une activité technique réservée aux spécialistes à un outil stratégique accessible à tous les professionnels. Les conseils pratiques que nous avons partagés vous permettront d'optimiser votre approche du web scraping chrome et d'en tirer le maximum de valeur.
Pour récapituler les points essentiels:
- Sélectionnez une extension d'extraction adaptée à vos besoins spécifiques
- Définissez clairement vos objectifs d'extraction avant de commencer
- Respectez toujours les aspects légaux et éthiques du web scraping
- Utilisez des outils capables de gérer le contenu dynamique moderne
- Structurez et nettoyez vos données pour les rendre réellement exploitables
- Automatisez l'ensemble du processus pour gagner un temps précieux
La révolution de l'extraction de données sans code a démocratisé l'accès à ces informations stratégiques, permettant à chaque professionnel de collecter et d'analyser les données dont il a besoin pour prendre des décisions éclairées. En intégrant ces pratiques à votre workflow, vous transformerez radicalement votre capacité à exploiter les données disponibles sur le web.
Pour aller plus loin dans l'automatisation de vos extractions de données et découvrir comment transformer le temps passé en copier-coller manuel en analyses stratégiques à forte valeur ajoutée, essayez Sheetly.ai gratuitement pendant 7 jours. Notre solution intelligente vous permet d'extraire et de structurer automatiquement les données depuis n'importe quelle source web, sans aucune connaissance technique requise.